[Twisted] Part 5: Twistier Poetry
本文由Dave的Part 5: Twistier Poetry翻譯而成,你可以由Part 1開始閱讀這個系列的文章,也可以在這裡找到整個系列的目錄。
首先,用戶端包含了一些像建立socket、從socket接收資料這種枯燥的程式碼。Twisted應該要提供實現這些事情的支援,讓我們不必每次寫新程式的時候都要去做這些事情。因為非同步I/O需要涉及一些棘手的例外處理,正如你在用戶端程式碼中所看到的。而且如果你希望你的程式可以跨平台執行,還有更多棘手的問題存在。如果你哪天下午有空,可以在Twisted原始碼中搜尋「WIN32」來看看這些corner cases。
目前用戶端的另外一個問題是有關錯誤處理方面。試著執行版本1的用戶端,對一個不是伺服器的埠口下載詩歌時,用戶端就會崩潰。我們可以修改這個用戶端程式,但透過今天使用的Twisted APIs來處理錯誤會更簡單。
最後,這個用戶端不能重複使用。如果另一個模組要透過我們的用戶端下載詩歌呢?如何讓其他模組知道詩歌已經下載完畢?我們無法寫一個簡單的涵式來回傳整首詩歌,這會阻塞其他模組直到整首詩歌被讀取完畢。這確實是個問題,但我們今天還沒要修正它,我們會在未來修正這個問題。
我們將會使用一些高層次的APIs和介面來解決第一、二個問題。Twisted框架是由眾多抽象層鬆散地組合起來的,學習Twisted就是學習這些層級中有那些東西可以用,例如APIs、介面、與實現。由於這份文章是一個介紹,所以我們不會研究每個抽象的細節,或者對Twisted的抽象進行深度的瞭解。我們只會看看最重要的部分來好好感受一下Twisted是如何組織這些抽象層,一旦你熟悉了Twisted的架構風格,你自己學習新的內容時就簡單多了。
一般來說,每個Twisted的抽象都只與一個特定的概念相關。例如,Part 4中的用戶端使用的IReadDescriptor,它就是「一個可以讀取位元組的file descriptor」的抽象。Twisted通常由定義介面來指定實現抽象的物件的行為。在學習Twisted中新的抽象時最重要的一點就是:
所以當你學習一個新的Twisted抽象時,要記住它做什麼和不做什麼。特別是如果某個早期的抽象A實現了F特性,那麼F特性就不太可能再由其他抽象實現。相反的如果抽象B需要F特性,它會使用抽象A而不是自己再去實現F(一般來說,B可能會繼承A或者引用一個實現A的物件)。
網路是一個複雜的主題,因此Twisted包含很多抽象。從底層的抽象開始,我們希望能更清楚的了解它們如何有效的在Twisted中整合在一起。
但是當我們在Twisted的外層處理問題時,可能很容易就忘了reactor的存在,在任何常見大小的Twisted中,我們的程式碼相對而言很少有直接使用reactor的APIs的部分,其他一些底層的抽象也是如此。我們在twisted-client-1中使用的file descriptor抽象就被很徹底的歸納進更高層級的概念中,以至於它們基本上消失在Twisted的程式中(它們依然在內部被使用,我們只是看不到而已)
對於file seacriptor抽象的消失,這個問題不大,讓Twisted處理非同步I/O的機制使我們可以更專注在我們試著解決的問題上。但是reactor不同,它永遠不會消失,當你選擇使用Twisted時,你也選擇了使用Reactor模式,這表示你要使用callback與多工合作的「回應式風格」去編寫你的程式。如果你想正確的使用Twisted,你必須牢記reactor的存在(與它的執行方式),在Part 6我們會對此有更多的說明,但現在要強調的是:
我們在說明新概念時還會有新的圖,但可以這麼說:這兩張圖你要牢記在腦海中。這兩張圖在我自己用Twisted撰寫程式時經常想到。
在我們深入了解程式碼時,有三個新的抽象要介紹:Transports、Protocols、以及 Protocol Factories。
如果你看一下ITransport中定義的方法,你不會看到任何接收資料的方法,這是因為Transport總是處理在連接中以非同步讀取資料的底層細節,然後透過callback將資料提供給我們。相同的道理,Transport物件中寫入相關的方法為了避免阻塞也不會立即寫入我們要發送的資料。告訴一個Transport寫入一些資料意味著「盡快送出這些資料,但是要避免產生阻塞」。當然,資料會依照我們提交的順序送出。
通常我們不會自己去實現Transport物件或在程式碼中建立它。相對的我們使用Twisted所提供,也就是在我們告訴reactor去建立一個連接時,為我們建立的實現。
嚴格來說,每一個Twisted的Protocols物件都實現了一個特定協定的連接。因此我們程式所建立的每個連接(對於伺服器來說就是每個接受的連接)都需要一個協定的實例。這使得Protocol實例成為儲存協定「Stateful」狀態與累積部分接收到的數據(因為我們使用非同步I/O接收任務大小區塊的位元組)的地方。
那麼Protocol實例如何知道它們該負責哪種連接呢?如果你觀察IProtocol的定義,你會發現一個叫做makeConnection的方法。這個方法是個callback,而且Twisted在呼叫它時會將Transport的實例作為它唯一的引數,這個Transport就是Protocol將要使用的連接。
Twisted包含了大量用於各種通訊協定的Protocol實現,你可以在twisted.protocols.basic中找到一些簡單的。建議你在編寫新的Protocol之前去檢查看看Twisted原始碼是否有現成的實現可供你使用。如果沒有那實現自己的Protocol是個好辦法,就像我們為詩歌用戶端所做的那樣。
正如你所猜到的那樣,Protocol Factory的API由IProtocolFactory來定義,同樣在interfaces模組中。Protocol Factory是Factory設計模式的一個範例,它們以一種直接了當的方式運作。buildProtocol方法會在每次呼叫時回傳一個Protocol實例,這就是Twisted為新連接建立新Protocol的方法。
在2.0版中,socket消失了,我們甚至不會引入socket模組,也不會以任何方式引入socket物件或file descriptor。相對的我們告訴reactor像這樣幫我們建立與詩歌伺服器的連接:
connectTCP方法是一個值得關注的地方。前兩個引數的用途應該不用多加說明,第三個引數是我們PoetryClientFactory類別的一個實例。這是針對詩歌用戶端的Protocol Factory,將它傳送給reactor允許Twisted根據需求創建PeotryProtocol的實例。
注意我們一開始沒有去實現Factory或Protocol,不像我們以前用戶端的PoetrySocket物件。相對的,我們繼承了Twisted在twisted.internet.protocol提供的基礎實現。主要的Factory的父類別是twisted.internet.protocol.Factory,但我們使用用戶端專用(處理建立連接而不是像伺服器一樣監聽連接)的ClientFactory子類別。
我們還可以利用Twisted的Factory類別為我們實現buildPeotocol的這個優勢,讓我們在子類別中呼叫父類別的實現:
父類別怎麼會知道要創建怎樣的Protocol呢?注意,我們在PoetryClientFactory中設定了一個protocol類別變數:
Factory父類別藉由我們設定的porotcol類別屬性,實例化這個類別(即PoetryProtocol)以實現buildProtocol,並且在新的實例上設定factory屬性參考到它的Factory父類別(譯註:即PoetryClientFactory),如圖8所示:
如上述般,Protocol物件的factory屬性允許以同一個Factory建立的Protocols間分享狀態。由於Factories都是由使用者的程式碼所建立,因此這個相同的屬性允許Protocol物件將通訊的結果回傳到一開始初始化請求的程式碼中,這部分我們將在Part 6中看到。
要注意儘管Protocol上的factory屬性參考到一個Protocol Factory的實例,而Factory的protocol屬性也參考到Protocol的類別,但通常一個Factory可以建立許多Protocol實例。
Protocol建立的第二步是使用makeConnection方法連接Procotoc與Transport。因為Twisted的父類別提供了預設的實現所以我們不需要自己實現這個方法。在預設的情況下,makeConnect在transport屬性上儲存了一個Transport的參考,並且設定connected屬性為True,如圖9所示:

一旦初始化到這一步,Protocol就可以開始執行它真正的工作,將底層的資料串流轉換為協定指定格式訊息的高層串流(也可以反向轉換),處理傳入資料的主要方法是dataReceived,我們的用戶端是這樣實現的:
每次呼叫dataReceved我們會以字串的形式得到一個新的位元組序列(資料),與非同步I/O一樣,我們不知道會接收到多少資料,所以我們必須給它一些緩衝空間,直到我們接收完一個完整的協定指定格式訊息。在我們的案例中,詩歌在連接關閉前都還沒完成,所以我們不斷的將位元組增加到.poem屬性中。
注意我們使用了Transport的getPeer方法來確認資料來自哪個伺服器,我們這樣做只是為了跟之前的用戶端保持一致,否則我們的程式碼根本不需要明確的使用Transport,因為我們不會向伺服器發送任何數據。
讓我們看看呼叫dataRecved方法時發生了什麼事情。在與我們2.0版本的用戶端相同的目錄中,有另一個用戶端叫做twisted-client-2/get-poetry-stack.py,它跟之前2.0的用戶端相同,除了dataRecved方法已經改變,像這樣:
有了這個改動,程式將會輸出一個stack trace(堆疊追蹤),然後在第一次收到一些資料時退出程式,你可以像這樣執行這個版本:
你會得到內容如下的stack trace:
那是我們在1.0版本用戶端使用的doRead callback!正如我們之前提到的,Twisted建立新抽象時會使用舊抽象,而不是取代替換掉舊抽象。因此仍然有一個IReadDescriptor實現在辛苦的工作,它是由Twisted而不是我們的程式碼來實現的。如果你好奇,Twisted的實現在twisted.internet.tcp中,如果你跟著程式碼,你會發現同一個物件實現了IWriteDescriptor與ITransport。所以IreadDescriptor實際上就是變相的Transport物件。我們可以用圖10視覺化的說明dataReceived callback:

一首詩歌完成下載後,PoetryProtocol物件就會通知它的PooetryClientFactory:
當傳輸的連接關閉時connectionLost callback就會被調用,reason引數是一個twisted.python.failure.Failure物件,其中的資訊包含連接是否被乾淨的關閉或是由於發生錯誤而關閉。而我們的用戶端只是忽略了這個數值並假設我們收到了整首詩歌。
工廠會在所有的詩歌都下載完畢後關閉reactor。我們再次假設我們的程式唯一做的事情只有下載詩歌,這使得PoetryClientFactory物件的重複使用性降低。我們會在下個章節解決這個問題,但是要注意poem_finish callback是如何追蹤剩下的詩歌數量:
如果我們寫了一個多執行緒的程式讓每個執行緒各自下載一首詩歌,我們就必須要使用一個鎖來保護這段程式碼,防止兩個或更多的執行緒同時調用poem_finish。但是在回應式系統中我們就不用擔心了,reactor一次只能進行一個callback,所以這種問題不會發生。
我們新的用戶端也可以處理連接失敗,比起1.0版本的用戶端更為優雅,以下是PoetryClientFactory類別處理連接失敗的程式碼:
要注意這個callback是在工廠上而不是協議上。由於協議只能在連接建立後才建立,而工廠才能在連接未成功建立時收到消息。
Abstract Expressionism
在Part 4中,我們使用了Twisted建立了我們第一個詩歌用戶端,它確實能夠很好的運作,但是仍然有進步的空間。首先,用戶端包含了一些像建立socket、從socket接收資料這種枯燥的程式碼。Twisted應該要提供實現這些事情的支援,讓我們不必每次寫新程式的時候都要去做這些事情。因為非同步I/O需要涉及一些棘手的例外處理,正如你在用戶端程式碼中所看到的。而且如果你希望你的程式可以跨平台執行,還有更多棘手的問題存在。如果你哪天下午有空,可以在Twisted原始碼中搜尋「WIN32」來看看這些corner cases。
目前用戶端的另外一個問題是有關錯誤處理方面。試著執行版本1的用戶端,對一個不是伺服器的埠口下載詩歌時,用戶端就會崩潰。我們可以修改這個用戶端程式,但透過今天使用的Twisted APIs來處理錯誤會更簡單。
最後,這個用戶端不能重複使用。如果另一個模組要透過我們的用戶端下載詩歌呢?如何讓其他模組知道詩歌已經下載完畢?我們無法寫一個簡單的涵式來回傳整首詩歌,這會阻塞其他模組直到整首詩歌被讀取完畢。這確實是個問題,但我們今天還沒要修正它,我們會在未來修正這個問題。
我們將會使用一些高層次的APIs和介面來解決第一、二個問題。Twisted框架是由眾多抽象層鬆散地組合起來的,學習Twisted就是學習這些層級中有那些東西可以用,例如APIs、介面、與實現。由於這份文章是一個介紹,所以我們不會研究每個抽象的細節,或者對Twisted的抽象進行深度的瞭解。我們只會看看最重要的部分來好好感受一下Twisted是如何組織這些抽象層,一旦你熟悉了Twisted的架構風格,你自己學習新的內容時就簡單多了。
一般來說,每個Twisted的抽象都只與一個特定的概念相關。例如,Part 4中的用戶端使用的IReadDescriptor,它就是「一個可以讀取位元組的file descriptor」的抽象。Twisted通常由定義介面來指定實現抽象的物件的行為。在學習Twisted中新的抽象時最重要的一點就是:
大多數高層級的抽象是建立在低層級的抽象的基礎上,而不是取代替換掉這些低層級抽象。
所以當你學習一個新的Twisted抽象時,要記住它做什麼和不做什麼。特別是如果某個早期的抽象A實現了F特性,那麼F特性就不太可能再由其他抽象實現。相反的如果抽象B需要F特性,它會使用抽象A而不是自己再去實現F(一般來說,B可能會繼承A或者引用一個實現A的物件)。
網路是一個複雜的主題,因此Twisted包含很多抽象。從底層的抽象開始,我們希望能更清楚的了解它們如何有效的在Twisted中整合在一起。
Loopiness in the Brain
至今為止我們所學到的最重要的抽象,實際上也是Twisted中最重要的抽象,就是reactor。在使用Twisted搭建的每個程式的中心,無論程式可能有多少層,都有一個reactor迴圈在不斷的驅動程式運作。在Twisted沒有其他的東西提供像reactor一樣的功能,實際上Twisted其餘大部分的內容都像是「讓X更容易使用reactor的東西」,X可能是提供網頁、建立資料庫查詢、或其他特定的功能。儘管可以像twisted-client-1那樣使用底層的APIs,但那樣做代表我們必須自己實現更多的內容,轉移到更高層級的抽象代表我們可以寫更少的程式碼(並且讓Twisted去處理與平台相關的corner cases)。但是當我們在Twisted的外層處理問題時,可能很容易就忘了reactor的存在,在任何常見大小的Twisted中,我們的程式碼相對而言很少有直接使用reactor的APIs的部分,其他一些底層的抽象也是如此。我們在twisted-client-1中使用的file descriptor抽象就被很徹底的歸納進更高層級的概念中,以至於它們基本上消失在Twisted的程式中(它們依然在內部被使用,我們只是看不到而已)
對於file seacriptor抽象的消失,這個問題不大,讓Twisted處理非同步I/O的機制使我們可以更專注在我們試著解決的問題上。但是reactor不同,它永遠不會消失,當你選擇使用Twisted時,你也選擇了使用Reactor模式,這表示你要使用callback與多工合作的「回應式風格」去編寫你的程式。如果你想正確的使用Twisted,你必須牢記reactor的存在(與它的執行方式),在Part 6我們會對此有更多的說明,但現在要強調的是:
圖5與圖6是這一系列文章中最重要的圖。
我們在說明新概念時還會有新的圖,但可以這麼說:這兩張圖你要牢記在腦海中。這兩張圖在我自己用Twisted撰寫程式時經常想到。
在我們深入了解程式碼時,有三個新的抽象要介紹:Transports、Protocols、以及 Protocol Factories。
TRANSPORTS
Transports抽象是由Twisted的interfaces模組中的ITransport定義。Transport代表可以收發位元組的單一個連接。對於我們的詩歌用戶端而言,Transport就像我們在早期版本所做的那樣-抽象了TCP連接,Twisted也支援UNIX Pipes與UDP sockets等I/O。Transport抽象可以代表任何這樣的連接,並為其代表的連接處理非同步I/O的細節部分。如果你看一下ITransport中定義的方法,你不會看到任何接收資料的方法,這是因為Transport總是處理在連接中以非同步讀取資料的底層細節,然後透過callback將資料提供給我們。相同的道理,Transport物件中寫入相關的方法為了避免阻塞也不會立即寫入我們要發送的資料。告訴一個Transport寫入一些資料意味著「盡快送出這些資料,但是要避免產生阻塞」。當然,資料會依照我們提交的順序送出。
通常我們不會自己去實現Transport物件或在程式碼中建立它。相對的我們使用Twisted所提供,也就是在我們告訴reactor去建立一個連接時,為我們建立的實現。
PROTOCOLS
Twisted的Protocols由interfaces模組中的IProtocol定義。正如你所預料的,Protocol物件實現協定。也就是說,一個特定的Twisted的Protocol實現,應該對應到一個具體網路通訊協定的實現,像FTP、IMAP或其它我們自己因需求而創建的協議。正如我們的詩歌協議,只要連接建立就將所有的詩歌內容全部發送,並且在發送完畢後關閉連接。嚴格來說,每一個Twisted的Protocols物件都實現了一個特定協定的連接。因此我們程式所建立的每個連接(對於伺服器來說就是每個接受的連接)都需要一個協定的實例。這使得Protocol實例成為儲存協定「Stateful」狀態與累積部分接收到的數據(因為我們使用非同步I/O接收任務大小區塊的位元組)的地方。
那麼Protocol實例如何知道它們該負責哪種連接呢?如果你觀察IProtocol的定義,你會發現一個叫做makeConnection的方法。這個方法是個callback,而且Twisted在呼叫它時會將Transport的實例作為它唯一的引數,這個Transport就是Protocol將要使用的連接。
Twisted包含了大量用於各種通訊協定的Protocol實現,你可以在twisted.protocols.basic中找到一些簡單的。建議你在編寫新的Protocol之前去檢查看看Twisted原始碼是否有現成的實現可供你使用。如果沒有那實現自己的Protocol是個好辦法,就像我們為詩歌用戶端所做的那樣。
PROTOCOL FACTORIES
所以每個連接都需要自己的Protocol,而這個Protocol可能是一個我們自己實現的類別的實例。由於我們讓Twisted負責處理建立連接,因此Twisted需要一個方法在每次建立新連接時可以「照需求(on demand)」建立適當的Protocol。建立Protocol實例就是Protocol Factories的工作。正如你所猜到的那樣,Protocol Factory的API由IProtocolFactory來定義,同樣在interfaces模組中。Protocol Factory是Factory設計模式的一個範例,它們以一種直接了當的方式運作。buildProtocol方法會在每次呼叫時回傳一個Protocol實例,這就是Twisted為新連接建立新Protocol的方法。
Get Poetry 2.0: First Blood.0
讓我們來看看Twisted詩歌用戶端的2.0版,它的程式碼在twisted-client-2/get-poetry.py。你可以像之前一樣執行它並且看到類似的輸出,所以這邊我就不貼出結果了。這也是最後一個會在收到位元組時輸出任務編號的版本。現在應該比較清楚所有的Twisted程式都是藉由交錯任務,並一次處理相對較小的資料區塊的這種方式來工作,我們仍然使用print statements來顯示關鍵時刻發生的事情,但用戶端以後就不會這麼冗長了。在2.0版中,socket消失了,我們甚至不會引入socket模組,也不會以任何方式引入socket物件或file descriptor。相對的我們告訴reactor像這樣幫我們建立與詩歌伺服器的連接:
factory = PoetryClientFactory(len(addresses))
from twisted.internet import reactor
for address in addresses:
host, port = address
reactor.connectTCP(host, port, factory)connectTCP方法是一個值得關注的地方。前兩個引數的用途應該不用多加說明,第三個引數是我們PoetryClientFactory類別的一個實例。這是針對詩歌用戶端的Protocol Factory,將它傳送給reactor允許Twisted根據需求創建PeotryProtocol的實例。
注意我們一開始沒有去實現Factory或Protocol,不像我們以前用戶端的PoetrySocket物件。相對的,我們繼承了Twisted在twisted.internet.protocol提供的基礎實現。主要的Factory的父類別是twisted.internet.protocol.Factory,但我們使用用戶端專用(處理建立連接而不是像伺服器一樣監聽連接)的ClientFactory子類別。
我們還可以利用Twisted的Factory類別為我們實現buildPeotocol的這個優勢,讓我們在子類別中呼叫父類別的實現:
def buildProtocol(self, address):
proto = ClientFactory.buildProtocol(self, address)
proto.task_num = self.task_num
self.task_num += 1
return proto父類別怎麼會知道要創建怎樣的Protocol呢?注意,我們在PoetryClientFactory中設定了一個protocol類別變數:
class PoetryClientFactory(ClientFactory):
task_num = 1
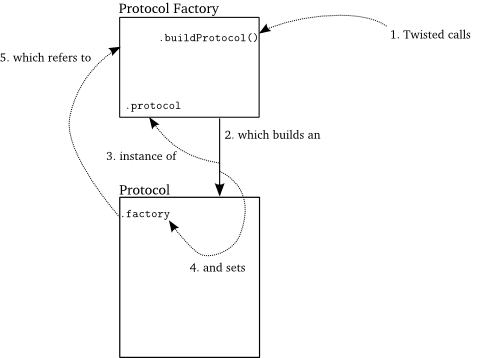
protocol = PoetryProtocol # tell base class what proto to buildFactory父類別藉由我們設定的porotcol類別屬性,實例化這個類別(即PoetryProtocol)以實現buildProtocol,並且在新的實例上設定factory屬性參考到它的Factory父類別(譯註:即PoetryClientFactory),如圖8所示:
圖8.Protocol誕生了
如上述般,Protocol物件的factory屬性允許以同一個Factory建立的Protocols間分享狀態。由於Factories都是由使用者的程式碼所建立,因此這個相同的屬性允許Protocol物件將通訊的結果回傳到一開始初始化請求的程式碼中,這部分我們將在Part 6中看到。
要注意儘管Protocol上的factory屬性參考到一個Protocol Factory的實例,而Factory的protocol屬性也參考到Protocol的類別,但通常一個Factory可以建立許多Protocol實例。
Protocol建立的第二步是使用makeConnection方法連接Procotoc與Transport。因為Twisted的父類別提供了預設的實現所以我們不需要自己實現這個方法。在預設的情況下,makeConnect在transport屬性上儲存了一個Transport的參考,並且設定connected屬性為True,如圖9所示:
圖9.Protocol遇見它的Transoprt
一旦初始化到這一步,Protocol就可以開始執行它真正的工作,將底層的資料串流轉換為協定指定格式訊息的高層串流(也可以反向轉換),處理傳入資料的主要方法是dataReceived,我們的用戶端是這樣實現的:
def dataReceived(self, data):
self.poem += data
msg = 'Task %d: got %d bytes of poetry from %s'
print msg % (self.task_num, len(data), self.transport.getPeer())每次呼叫dataReceved我們會以字串的形式得到一個新的位元組序列(資料),與非同步I/O一樣,我們不知道會接收到多少資料,所以我們必須給它一些緩衝空間,直到我們接收完一個完整的協定指定格式訊息。在我們的案例中,詩歌在連接關閉前都還沒完成,所以我們不斷的將位元組增加到.poem屬性中。
注意我們使用了Transport的getPeer方法來確認資料來自哪個伺服器,我們這樣做只是為了跟之前的用戶端保持一致,否則我們的程式碼根本不需要明確的使用Transport,因為我們不會向伺服器發送任何數據。
讓我們看看呼叫dataRecved方法時發生了什麼事情。在與我們2.0版本的用戶端相同的目錄中,有另一個用戶端叫做twisted-client-2/get-poetry-stack.py,它跟之前2.0的用戶端相同,除了dataRecved方法已經改變,像這樣:
def dataReceived(self, data):
traceback.print_stack()
os._exit(0)有了這個改動,程式將會輸出一個stack trace(堆疊追蹤),然後在第一次收到一些資料時退出程式,你可以像這樣執行這個版本:
python twisted-client-2/get-poetry-stack.py 10000你會得到內容如下的stack trace:
File "twisted-client-2/get-poetry-stack.py", line 125, in
poetry_main()
... # I removed a bunch of lines here
File ".../twisted/internet/tcp.py", line 463, in doRead # Note the doRead callback
return self.protocol.dataReceived(data)
File "twisted-client-2/get-poetry-stack.py", line 58, in dataReceived
traceback.print_stack()那是我們在1.0版本用戶端使用的doRead callback!正如我們之前提到的,Twisted建立新抽象時會使用舊抽象,而不是取代替換掉舊抽象。因此仍然有一個IReadDescriptor實現在辛苦的工作,它是由Twisted而不是我們的程式碼來實現的。如果你好奇,Twisted的實現在twisted.internet.tcp中,如果你跟著程式碼,你會發現同一個物件實現了IWriteDescriptor與ITransport。所以IreadDescriptor實際上就是變相的Transport物件。我們可以用圖10視覺化的說明dataReceived callback:
圖10.dataReceived callback
一首詩歌完成下載後,PoetryProtocol物件就會通知它的PooetryClientFactory:
def connectionLost(self, reason):
self.poemReceived(self.poem)
def poemReceived(self, poem):
self.factory.poem_finished(self.task_num, poem)當傳輸的連接關閉時connectionLost callback就會被調用,reason引數是一個twisted.python.failure.Failure物件,其中的資訊包含連接是否被乾淨的關閉或是由於發生錯誤而關閉。而我們的用戶端只是忽略了這個數值並假設我們收到了整首詩歌。
工廠會在所有的詩歌都下載完畢後關閉reactor。我們再次假設我們的程式唯一做的事情只有下載詩歌,這使得PoetryClientFactory物件的重複使用性降低。我們會在下個章節解決這個問題,但是要注意poem_finish callback是如何追蹤剩下的詩歌數量:
...
self.poetry_count -= 1
if self.poetry_count == 0:
...如果我們寫了一個多執行緒的程式讓每個執行緒各自下載一首詩歌,我們就必須要使用一個鎖來保護這段程式碼,防止兩個或更多的執行緒同時調用poem_finish。但是在回應式系統中我們就不用擔心了,reactor一次只能進行一個callback,所以這種問題不會發生。
我們新的用戶端也可以處理連接失敗,比起1.0版本的用戶端更為優雅,以下是PoetryClientFactory類別處理連接失敗的程式碼:
def clientConnectionFailed(self, connector, reason):
print 'Failed to connect to:', connector.getDestination()
self.poem_finished()要注意這個callback是在工廠上而不是協議上。由於協議只能在連接建立後才建立,而工廠才能在連接未成功建立時收到消息。
A SIMPLER CLIENT
雖然我們新的用戶端已經相當的簡單,如果我們省略掉任務編號它可以更簡單。畢竟我們的用戶端只需要跟詩歌有關,這裡有個簡化的2.1版本在twisted-client-2/get-poetry-simple.py。Wrapping Up
第2版的用戶端使用的抽象對於那些Twisted高手應該非常熟悉。如果我們要的只是一個再命令列輸出一些詩歌然後就退出的用戶端,我們甚至可以在這邊停下,說我們的程式已經完成了。但是如果我們需要一些可以重複使用的程式碼,一些我們可以嵌入在較大型的程式中,讓程式可以下載詩歌的同時也做些其他事情的程式,那我們還有一些工作要做。我們在Part 6會首先介紹這部分。Suggested Exercises
- 如果在給定的時間過後詩歌沒有下載完成,使用callLater讓用戶端逾時。使用transport上的loseConnection方法在逾時時關閉連接,並且如果詩歌準時下載完成不要忘記取消逾時。
- 使用stacktrace方法去分析當connectionLost被調用時的callback序列。
留言
張貼留言