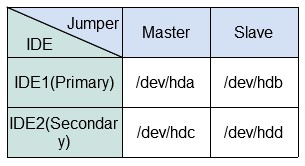
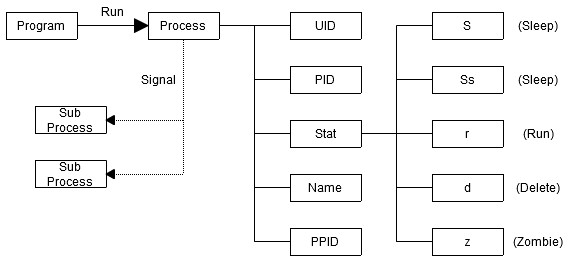
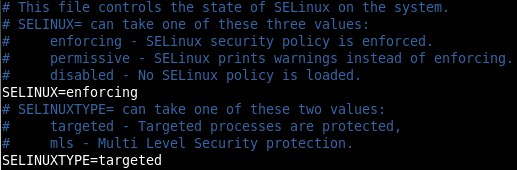
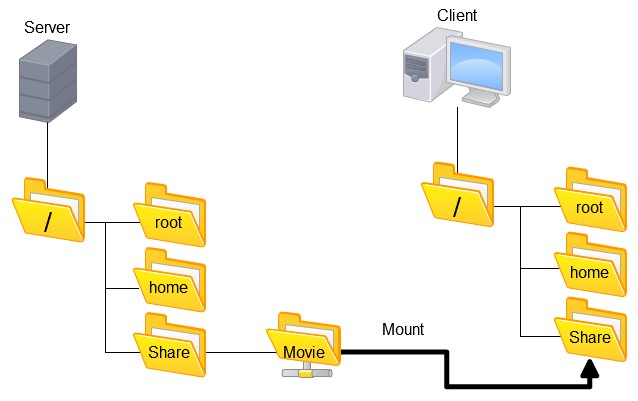
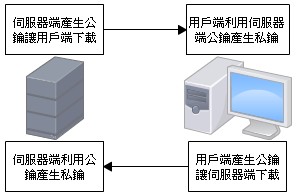
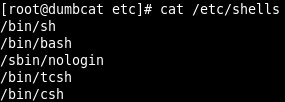
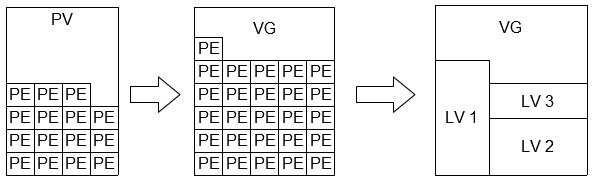
[RHCE] Install And Manage Software

USE RPM 在過去沒有rpm的時後,使用者想在系統上安裝軟體是相當麻煩的。要先確定作業系統與環境是否符合、設定軟體的參數、然後還要編譯過才能使用。所以Red Hat開發出rpm這個機制,將開發完的軟體先經過編譯,打包成rpm的封裝檔案。 然後利用資料庫去紀錄檔案的相關資訊、相依檔案、系統需求等等。 當使用者得到rpm檔案之後,rpm會利用軟體的資料庫去檢查環境是否符合、相依檔案是否存在等等。如果條件都符合軟體需求,則可使用簡單的指令快速安裝這些軟體。甚至對於將來可能需要的升級、反安裝,也都可以輕鬆完成。 rpm可以用 -q 參數來查尋軟體的相關資訊。 #rpm -q [軟體名稱] 可以查詢該軟體是否安裝,這邊軟體名稱必須輸入完整。例如要查詢qemu-kvm-common-1.5.3-60.el7.x86_64,就必須輸入qemu-kvm-common。或者使用 #rpm -q[參數] [軟體名稱] ,可以查詢其他的資訊。 a: 查詢所有已安裝的軟體名稱,使用qa時後面不用接軟體名稱。 i: 查詢該軟體的詳細資訊。 l: 查詢該軟體安裝後所有的檔案及目錄的完整名稱。 c: 查詢該軟體安裝後所有的設定檔名稱。 d: 查詢該軟體安裝後所有的說明檔名稱。 R: 查詢該軟體安裝時所需要的相依檔案名稱及版本要求。 f: 此參數後面接的為目錄或檔名,可以查詢該目錄或檔案屬於哪個已安裝軟體。 p: 此參數是配合上述參數針對未安裝的rpm檔進行查詢。 --scripts: 查詢軟體安裝或移除時直行的shell scripts。 --changelog: 查詢軟體的更新紀錄檔。 rpm也可以用來安裝以及更新軟體。當我們要安裝一個軟體時,可以輸入 #rpm -ivh [軟體名稱] 。 i: 安裝(install)。 v: 安裝時顯示更多的資訊畫面。 h: 安裝時顯示安裝進度。 當我們要對現有的軟體做更新時,可輸入 #rpm -Uvh [軟體名稱] 或 #rpm -Fvh [軟體名稱] 。 U: 如果軟體並未安裝過,則會直接安裝,而已安裝的軟體則自動更新。 F: ...