[Twisted] Part 4: Twisted Poetry
本文由Dave的Part 4: Twisted Poetry翻譯而成,你可以由Part 1開始閱讀這個系列的文章,也可以在這裡找到整個系列的目錄。
然後像這樣執行用戶端:
然後你會看到一些像這樣的輸出:
這些結果就像我們的非Twisted非同步用戶端一樣,這並不奇怪,因為它們基本上在做相同的事情。我們來看看原始碼,了解它是如何執行的。用你的編輯器打開用戶端,方便查看我們在討論的程式碼。
首先程式透過建立了一個PoetrySocket的物件來啟動Twisted用戶端,PoetrySocket利用建立一個網路socket、連結到伺服器、與切換到非阻塞模式來初始化自己:
以後我們會達到不使用socket的抽象層級上,但現在我們仍然需要socket。在建立網路連線後,PoetrySocket透過addReader方法將自己傳給reactor:
這個方法提供Twisted一個你想要監視的傳入資料的file descriptor。為什麼我們要傳給Twisted一個物件而不是一個file descriptor或callback函式呢?而且Twisted如何在不包含任何詩歌服務特定的程式碼時,知道如何處理我們的物件?相信我,我已經看過了。打開twisted.internet.interfaces模組然後跟我一起來看看。
介面的主要目的之一就是documentation(文件化)。作為一個Python的程式設計師,你毫無疑問的熟悉Duck Typing,其概念是物件的類型原則上不是由它在類別層級的位置所定義,而是由它對世界呈現的公開介面所定義,因此就duck typing而言,呈現相同的公開介面(例如走路像鴨子,叫聲像鴨子...)的兩個物件就是相同的(鴨子!),那一個介面就是以稍微形式化的方式指定它像個鴨子一樣走路的意思。
關於術語的簡要說明:以zope.interface來說,一個類別「實現(implements)」了一個介面,而類別的實例「提供(provide)」了這個介面(假設它是根據我們調用由介面所定義的方法而建立的實例),我們將在討論中試著繼續使用這個術語。
跳過twisted.internet.interfaces中其他的程式碼直到你找到addReader方法的定義,它在IReactorFDSet介面中被宣告,應該看起來像這樣:
IReactorFDSet是Twisted的reactor所提供的介面之一,因此任何Twisted的reactor都有一個叫做addReader的方法,它的執行方式就如上面docstring所描述一樣。這個方法的說明沒有self引數,因為它只在意定義一個公共介面,而self引數是介面實現時的一部分(也就是說呼叫者不用明確的傳遞self引數)。介面物件永遠不會被實例化,或者被實際的實現來繼承。
根據上面的docstring,addReader的reader引數是要實現IreadDescriptor介面的。這也就意味我們的PoetrySocket物件也必須這樣做。
在模組中找到這個介面,我們可以看到:
並且你會在PoetrySocket類別中找到一個doRead方法,當它被Twisted的reactor呼叫時,它會使用非同步的方式從socket讀取資料,所以doRead實際上是一個callback,但不是直接將它傳給Twisted的reactor,而是傳送一個有doRead方法的物件。這也是Twisted框架的慣例-用傳送一個提供某個介面的物件代替傳送一個方法,這讓我們可以使用一個引數就傳送一組相關的callbacks(介面定義的方法)。這也讓callbacks透過儲存在物件上的共享狀態來進行相互間的通訊。
那麼在PoetrySocket中還提供了那些callback呢?注意到IReadDescriptor是IFileDescriptor的一個子類別,這也表示任何一個提供IReadDescriptor的物件都必須提供IFileDescriptor。而且如果你繼續往下看程式碼,你會看到:
我省略了docstring,但這些callback的功能從名字上就可以了解:fileno應該回傳我們想要監視的file descriptor,而connectionLost會在連線結束時被呼叫。你可以看到我們的PoetrySocket物件也提供了這些方法。
最後,IFileDescriptor繼承了ILooggingContext。我不打算在這邊展示,但這就是為什麼我們需要包含logPrefix這個callback,你可以在interface模組中找到詳細的說明。
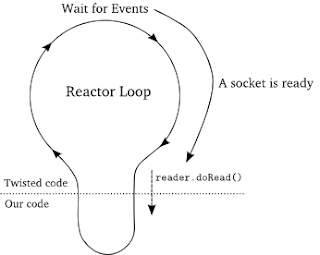
doRead callback是最重要的callback,Twisted呼叫它來告訴我們某些資料已經準備好可以從socket中讀取了,我們可以透過圖7想像這個過程:
每次callback被調用時,我們需要盡可能的讀取資料,然後以非阻塞的方式的停止。如同我們在Part 3所說的,Twisted不會因為異常狀況而停止(除非有必要的阻塞),我們可以產生異常狀況然後看看會發生甚麼事情,在同樣的目錄中有twisted-client-1/get-poetry-broken.py這個出問題的用戶端,這個用戶端與之前看到的用戶端相同,但有兩個例外狀況:
現在試著執行這個出問題的用戶端:
你會得到一些像這樣的輸出:
可能除了任務的完成順序不太一致外,這看起來就像我們原本的阻塞式用戶端。這是因為這個用戶端是一個阻塞式的。在我們的callback中藉由呼叫阻塞式的recv,將我們非同步(譯註:非阻塞式)的Twisted程式轉變為同步(譯註:阻塞式)程式。所以我們承受了使用select迴圈的複雜性但沒有享受到任何非同步的好處。
Twisted提供的事件迴圈的多工能力是互相合作的,Twisted會告訴我們什麼時候可以讀取或寫入一個file descriptor,但我們必須在沒有阻塞的狀況下盡可能的讀寫。同時我們也必須避免呼叫其他類型的阻塞,如os.system。除此之外,如果我們有長時間計算(占用CPU)的任務,最好將任務分割為較小的部分,以便I/O任務盡可能地繼續執行。
注意我們出問題的用戶端還是有效的,它確實可以下載我們要求的所有詩歌,只是它無法利用非同步I/O的效率。現在你也許會注意到,出問題的用戶端仍然比原本阻塞式的用戶端還要快,這是因為出問題的用戶端在程式開始時就跟所有伺服器連結,伺服器一旦建立連接就開始發送資料,並且作業系統會為我們緩衝(還沒到達緩衝區上限時)一些傳入但還沒讀取的資料,使得我們的阻塞式用戶端可以有效率地從其他伺服器接收資料,即使它一次只能讀取一個伺服器的資料。
但這種小把戲只適用於少量資料的狀況下,例如我們的短詩歌,如果我們下載的是三首兩千萬字的史詩冒險紀錄,一個駭客企圖透過撰寫世界最偉大的LISP直譯器來贏得他的真愛;這樣作業系統的緩衝區很快就會被填滿,如此一來我們出問題的用戶端會比原本的阻塞式用戶端更沒效率。
Writer等同於我們在用戶端使用的Reader API,它們對於我們想要監視的用於傳送資料的file descriptor使用類似的方式。請參閱interface文件以獲得更多細節。讀取與寫入有各自的APIs是因為select區分了這兩種事件(一個file descriptor可分別用於讀取或寫入),當然也可以在同一個descriptor等待這兩種事件。
在Part 5,我們將使用更高層級的抽象方法來編寫我們Twisted詩歌用戶端的第二個版本,並學習更多的Twisted介面跟APIs。
Our First Twisted Client
雖然Twisted可能較常用於撰寫伺服器,但用戶端比伺服器更簡單,我們盡量從簡單的開始。讓我們嘗試用Twisted撰寫第一個詩歌用戶端。原始碼在twisted-client-1/get-poetry.py,像以前一樣先啟動三個詩歌伺服器:python blocking-server/slowpoetry.py --port 10000 poetry/ecstasy.txt --num-bytes 30
python blocking-server/slowpoetry.py --port 10001 poetry/fascination.txt
python blocking-server/slowpoetry.py --port 10002 poetry/science.txt然後像這樣執行用戶端:
python twisted-client-1/get-poetry.py 10000 10001 10002然後你會看到一些像這樣的輸出:
Task 1: got 60 bytes of poetry from 127.0.0.1:10000
Task 2: got 10 bytes of poetry from 127.0.0.1:10001
Task 3: got 10 bytes of poetry from 127.0.0.1:10002
Task 1: got 30 bytes of poetry from 127.0.0.1:10000
Task 3: got 10 bytes of poetry from 127.0.0.1:10002
Task 2: got 10 bytes of poetry from 127.0.0.1:10001
...
Task 1: 3003 bytes of poetry
Task 2: 623 bytes of poetry
Task 3: 653 bytes of poetry
Got 3 poems in 0:00:10.134220這些結果就像我們的非Twisted非同步用戶端一樣,這並不奇怪,因為它們基本上在做相同的事情。我們來看看原始碼,了解它是如何執行的。用你的編輯器打開用戶端,方便查看我們在討論的程式碼。
注意:正如我在Part 1所提到的,我們將透過一些底層的APIs來使用Twisted。透過這種方法我們可以繞過Twisted中一些抽象層,這樣我們可以由內而外學習Twisted,但這也表示許多在我們學習中用到的APIs在現實應用中並不常見到,請記住這些程式只是用作學習時練習,並不是寫出一個真正的軟體的範例。
首先程式透過建立了一個PoetrySocket的物件來啟動Twisted用戶端,PoetrySocket利用建立一個網路socket、連結到伺服器、與切換到非阻塞模式來初始化自己:
self.sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.sock.connect(address)
self.sock.setblocking(0)以後我們會達到不使用socket的抽象層級上,但現在我們仍然需要socket。在建立網路連線後,PoetrySocket透過addReader方法將自己傳給reactor:
# tell the Twisted reactor to monitor this socket for reading
from twisted.internet import reactor
reactor.addReader(self)這個方法提供Twisted一個你想要監視的傳入資料的file descriptor。為什麼我們要傳給Twisted一個物件而不是一個file descriptor或callback函式呢?而且Twisted如何在不包含任何詩歌服務特定的程式碼時,知道如何處理我們的物件?相信我,我已經看過了。打開twisted.internet.interfaces模組然後跟我一起來看看。
Twisted Interfaces
在Twisted中有許多被稱為interface的子模組,每個都定義了一組Interface類別。從8.0版開始,Twisted使用zope.interface做為這些類別的基礎類別,但這些細節對我們來說並不重要,我們只關心Twisted本身的介面子類別,如同你現在所看到的這些。介面的主要目的之一就是documentation(文件化)。作為一個Python的程式設計師,你毫無疑問的熟悉Duck Typing,其概念是物件的類型原則上不是由它在類別層級的位置所定義,而是由它對世界呈現的公開介面所定義,因此就duck typing而言,呈現相同的公開介面(例如走路像鴨子,叫聲像鴨子...)的兩個物件就是相同的(鴨子!),那一個介面就是以稍微形式化的方式指定它像個鴨子一樣走路的意思。
關於術語的簡要說明:以zope.interface來說,一個類別「實現(implements)」了一個介面,而類別的實例「提供(provide)」了這個介面(假設它是根據我們調用由介面所定義的方法而建立的實例),我們將在討論中試著繼續使用這個術語。
跳過twisted.internet.interfaces中其他的程式碼直到你找到addReader方法的定義,它在IReactorFDSet介面中被宣告,應該看起來像這樣:
def addReader(reader):
"""
I add reader to the set of file descriptors to get read events for.
@param reader: An L{IReadDescriptor} provider that will be checked for
read events until it is removed from the reactor with
L{removeReader}.
@return: C{None}.
"""IReactorFDSet是Twisted的reactor所提供的介面之一,因此任何Twisted的reactor都有一個叫做addReader的方法,它的執行方式就如上面docstring所描述一樣。這個方法的說明沒有self引數,因為它只在意定義一個公共介面,而self引數是介面實現時的一部分(也就是說呼叫者不用明確的傳遞self引數)。介面物件永遠不會被實例化,或者被實際的實現來繼承。
注意1:技術上講,IReactorFDSet只能由支援等待file descriptor的reactor所提供,據我所知,目前所有的reactor都包含這個介面。
注意2:使用介面並不僅僅是為了documentation。zope.interface允許你明確地宣告一個類別來實現一個或多個介面,並附帶在運行時檢查這些宣告的機制。同時也支援調適的概念,能為一個不支援直接介面的物件提供一個動態的介面,但我們不打算研究這些更高級的案例。
注意3:你可能已經注意到介面與最近添加到Python中Abstract Base Classes(抽象類別)的相似性了。這裡我們並不去探究它們之間的相似處與差異。若你有興趣,可以讀讀Twisted專案的創始人Glyph寫的關於這個話題的文章。
根據上面的docstring,addReader的reader引數是要實現IreadDescriptor介面的。這也就意味我們的PoetrySocket物件也必須這樣做。
在模組中找到這個介面,我們可以看到:
class IReadDescriptor(IFileDescriptor):
def doRead():
"""
Some data is available for reading on your descriptor.
"""並且你會在PoetrySocket類別中找到一個doRead方法,當它被Twisted的reactor呼叫時,它會使用非同步的方式從socket讀取資料,所以doRead實際上是一個callback,但不是直接將它傳給Twisted的reactor,而是傳送一個有doRead方法的物件。這也是Twisted框架的慣例-用傳送一個提供某個介面的物件代替傳送一個方法,這讓我們可以使用一個引數就傳送一組相關的callbacks(介面定義的方法)。這也讓callbacks透過儲存在物件上的共享狀態來進行相互間的通訊。
那麼在PoetrySocket中還提供了那些callback呢?注意到IReadDescriptor是IFileDescriptor的一個子類別,這也表示任何一個提供IReadDescriptor的物件都必須提供IFileDescriptor。而且如果你繼續往下看程式碼,你會看到:
class IFileDescriptor(ILoggingContext):
"""
A file descriptor.
"""
def fileno():
...
def connectionLost(reason):
...我省略了docstring,但這些callback的功能從名字上就可以了解:fileno應該回傳我們想要監視的file descriptor,而connectionLost會在連線結束時被呼叫。你可以看到我們的PoetrySocket物件也提供了這些方法。
最後,IFileDescriptor繼承了ILooggingContext。我不打算在這邊展示,但這就是為什麼我們需要包含logPrefix這個callback,你可以在interface模組中找到詳細的說明。
注意:你可能注意到doRead回傳了一個特殊的值來指示socket關閉連線,我如何知道要怎樣做的?基本上,沒有它程式是無法執行的,而且我偷看了Twisted在實現相同介面時需要做些什麼。因為某些軟體的文件是錯誤或不完整的,你可能需要好好研究一下,也許當你搞清楚的時候,我已經完成了Part 5。
More on Callbacks
我們新的Twisted用戶端與我們原本的非同步用戶端非常相似,兩個用戶端都連接了自己的socket,並以非同步的方式從各自的socket讀取資料,主要的差別是Twisted不需要自己的select迴圈-它使用Twisted的reactor來代替。doRead callback是最重要的callback,Twisted呼叫它來告訴我們某些資料已經準備好可以從socket中讀取了,我們可以透過圖7想像這個過程:

圖7.doRead callback
每次callback被調用時,我們需要盡可能的讀取資料,然後以非阻塞的方式的停止。如同我們在Part 3所說的,Twisted不會因為異常狀況而停止(除非有必要的阻塞),我們可以產生異常狀況然後看看會發生甚麼事情,在同樣的目錄中有twisted-client-1/get-poetry-broken.py這個出問題的用戶端,這個用戶端與之前看到的用戶端相同,但有兩個例外狀況:
- 這個出問題的用戶端並沒有讓socket成為非阻塞式的。
- doRead不停地讀位元組(而且可能發生阻塞)直到socket被關閉。
現在試著執行這個出問題的用戶端:
python twisted-client-1/get-poetry-broken.py 10000 10001 10002你會得到一些像這樣的輸出:
Task 1: got 3003 bytes of poetry from 127.0.0.1:10000
Task 3: got 653 bytes of poetry from 127.0.0.1:10002
Task 2: got 623 bytes of poetry from 127.0.0.1:10001
Task 1: 3003 bytes of poetry
Task 2: 623 bytes of poetry
Task 3: 653 bytes of poetry
Got 3 poems in 0:00:10.132753可能除了任務的完成順序不太一致外,這看起來就像我們原本的阻塞式用戶端。這是因為這個用戶端是一個阻塞式的。在我們的callback中藉由呼叫阻塞式的recv,將我們非同步(譯註:非阻塞式)的Twisted程式轉變為同步(譯註:阻塞式)程式。所以我們承受了使用select迴圈的複雜性但沒有享受到任何非同步的好處。
Twisted提供的事件迴圈的多工能力是互相合作的,Twisted會告訴我們什麼時候可以讀取或寫入一個file descriptor,但我們必須在沒有阻塞的狀況下盡可能的讀寫。同時我們也必須避免呼叫其他類型的阻塞,如os.system。除此之外,如果我們有長時間計算(占用CPU)的任務,最好將任務分割為較小的部分,以便I/O任務盡可能地繼續執行。
注意我們出問題的用戶端還是有效的,它確實可以下載我們要求的所有詩歌,只是它無法利用非同步I/O的效率。現在你也許會注意到,出問題的用戶端仍然比原本阻塞式的用戶端還要快,這是因為出問題的用戶端在程式開始時就跟所有伺服器連結,伺服器一旦建立連接就開始發送資料,並且作業系統會為我們緩衝(還沒到達緩衝區上限時)一些傳入但還沒讀取的資料,使得我們的阻塞式用戶端可以有效率地從其他伺服器接收資料,即使它一次只能讀取一個伺服器的資料。
但這種小把戲只適用於少量資料的狀況下,例如我們的短詩歌,如果我們下載的是三首兩千萬字的史詩冒險紀錄,一個駭客企圖透過撰寫世界最偉大的LISP直譯器來贏得他的真愛;這樣作業系統的緩衝區很快就會被填滿,如此一來我們出問題的用戶端會比原本的阻塞式用戶端更沒效率。
Wrapping Up
我沒有過多解釋我們的第一個Twisted詩歌用戶端。你可能注意到了,在PoetrySocket不再等待任何詩歌後,connectionLost這個callback會關閉reactor。這不是一個多厲害的技術,因為它假設我們的程式中除了下載詩歌外沒有做其他的事情,不過它確實顯示了removeReactor與getReactor這兩個兩個低階的APIs。Writer等同於我們在用戶端使用的Reader API,它們對於我們想要監視的用於傳送資料的file descriptor使用類似的方式。請參閱interface文件以獲得更多細節。讀取與寫入有各自的APIs是因為select區分了這兩種事件(一個file descriptor可分別用於讀取或寫入),當然也可以在同一個descriptor等待這兩種事件。
在Part 5,我們將使用更高層級的抽象方法來編寫我們Twisted詩歌用戶端的第二個版本,並學習更多的Twisted介面跟APIs。
Suggested Exercises
- 修復用戶端,讓它連接到伺服器失敗時不會導致程式崩潰。
- 如果在給定的時間過後詩歌沒有下載完成,使用callLater讓用戶端逾時。閱讀關於callLater回傳值的說明,這樣如果詩歌準時完成下載,你可以取消逾時。
留言
張貼留言